
Facet
See yourself, sharpened. Build the identity model behind your search, then turn it into focused resumes, prep, and outreach.
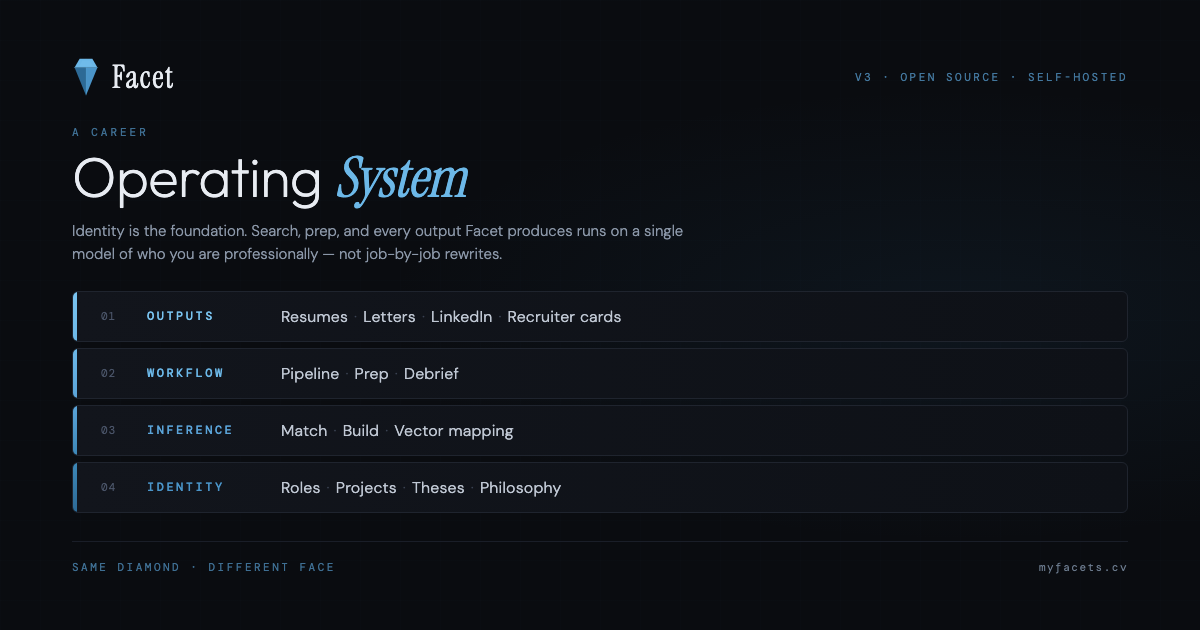
Identity is the foundation. Every output Facet produces — resumes, letters, LinkedIn copy, recruiter cards — runs on a single model of who you are professionally, not job-by-job rewrites. Same diamond. Different face.
Most AI tools generate from a one-shot prompt. Facet extracts your identity from the raw signal of what you've actually done, then refines it across iterative passes. Correction over creation. You explain why you made each decision, and the model surfaces the judgment your resume never captured.

Public surface, active arc, lived evidence. Three layers of identity feed every workspace below. The bottom is what's actually true; the top is what each audience sees.

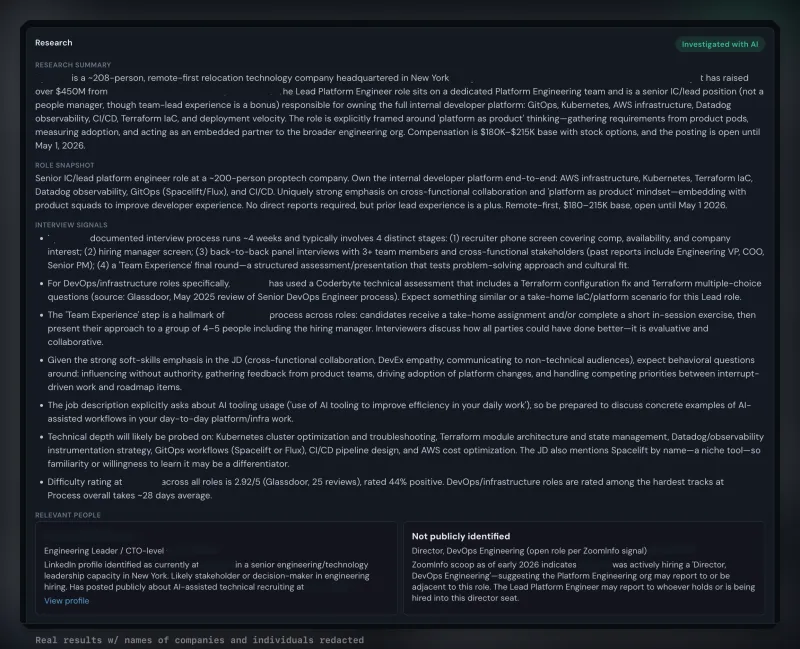
Research
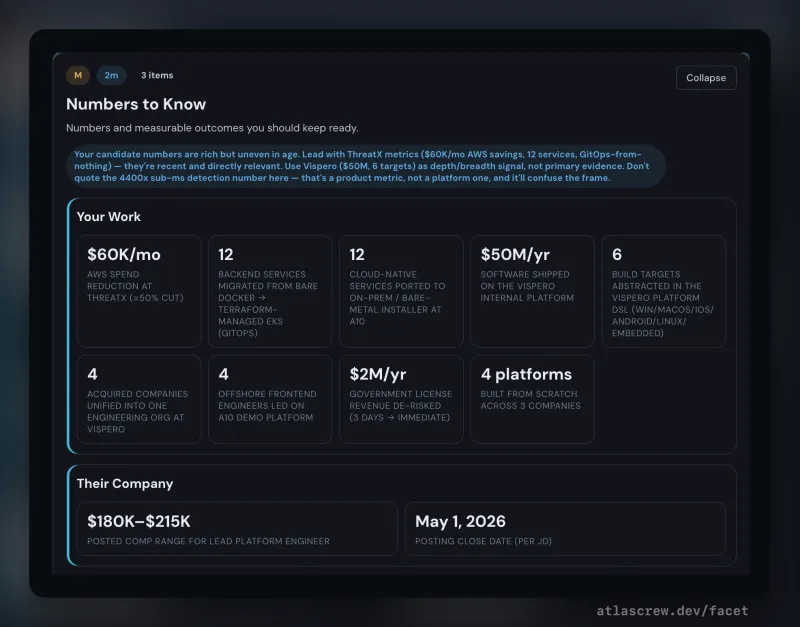
Research runs in three tiers. Discovery infers your search profile and evaluates role fit per listing. Pipeline enriches entries you pursue with company context and JD analysis. Pre-prep does the deep per-person research on interviewers you name — because AI guessing who's interviewing tends to be wrong in ways that cost trust. You supply the names, Facet does the intel.
Pipeline
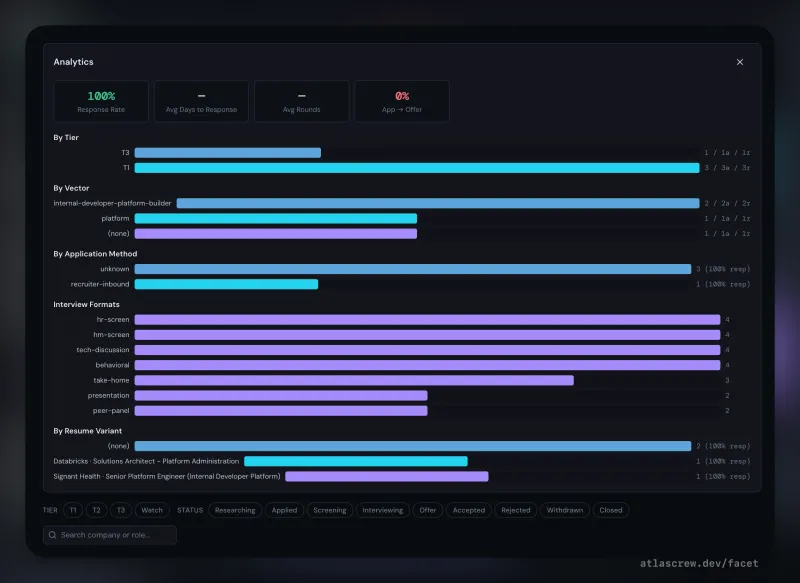
Rounds as first-class objects — schedule each round, capture interviewer names as you learn them, link each round to its prep deck. Company, role, compensation, JD storage, outcome history per round. A cross-job calendar view surfaces prep-readiness beside every scheduled interview (in design).
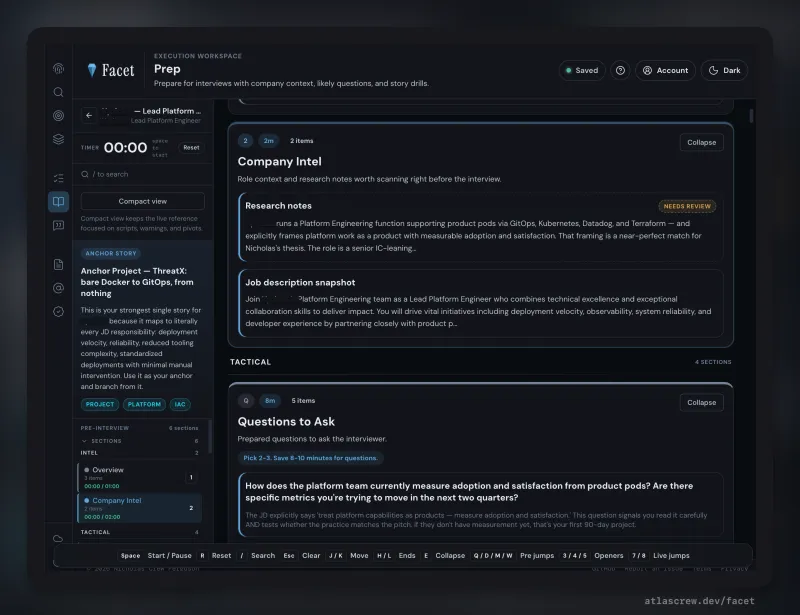
Prep
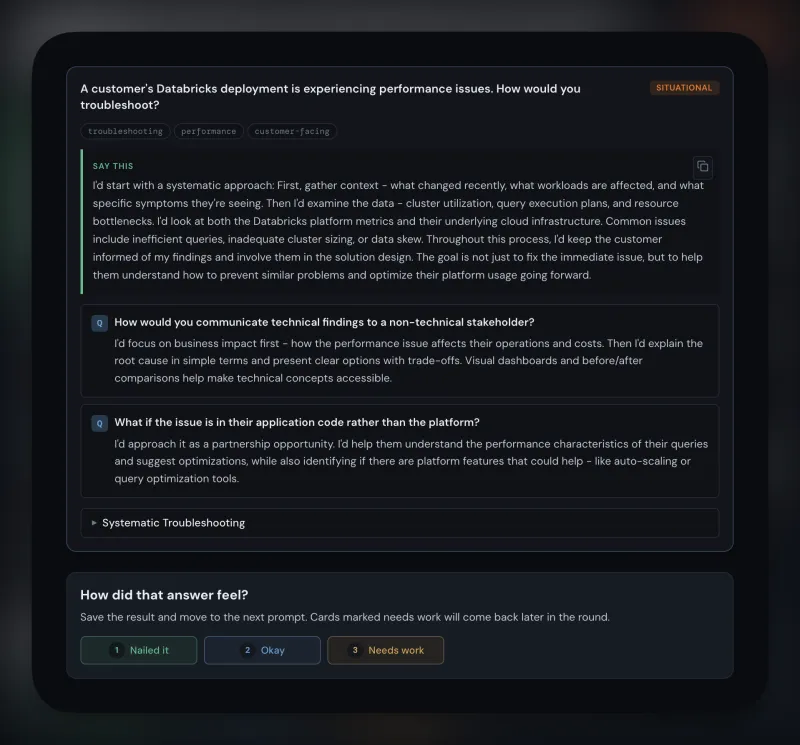
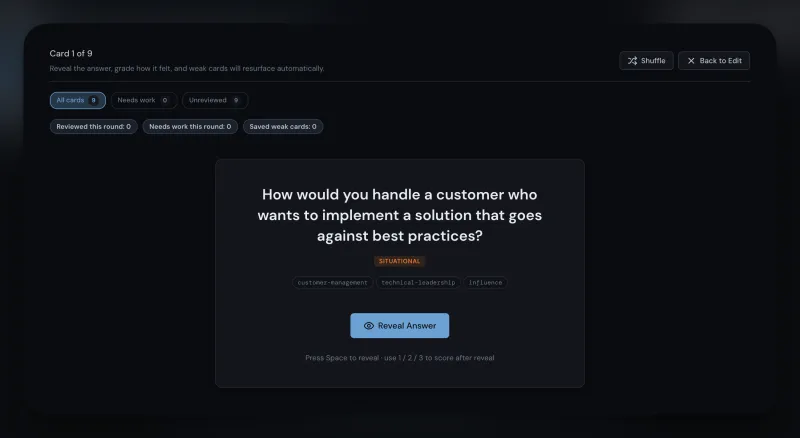
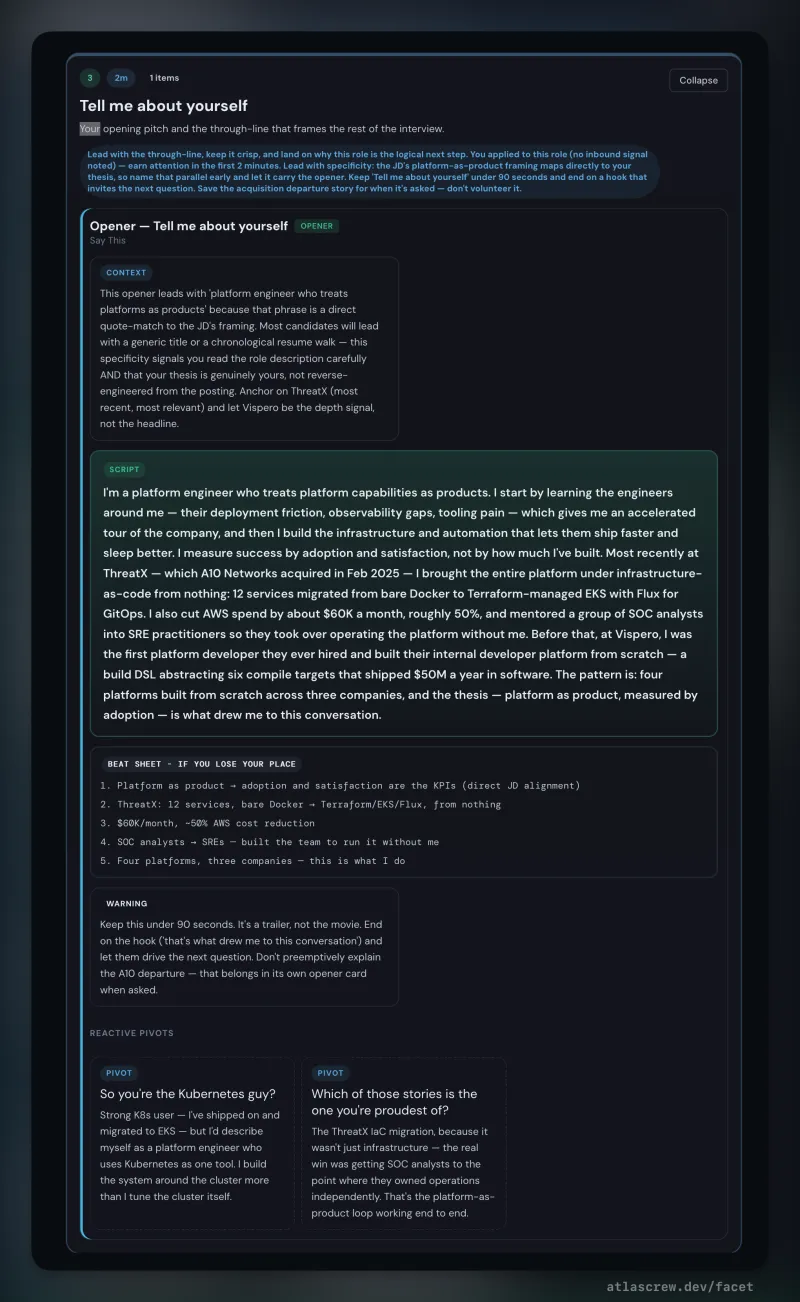
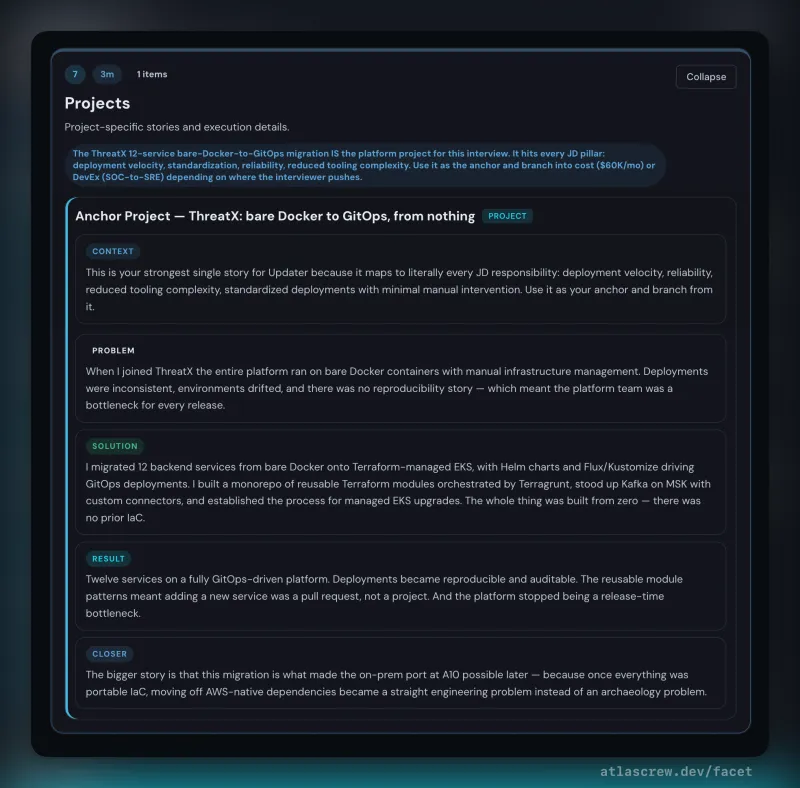
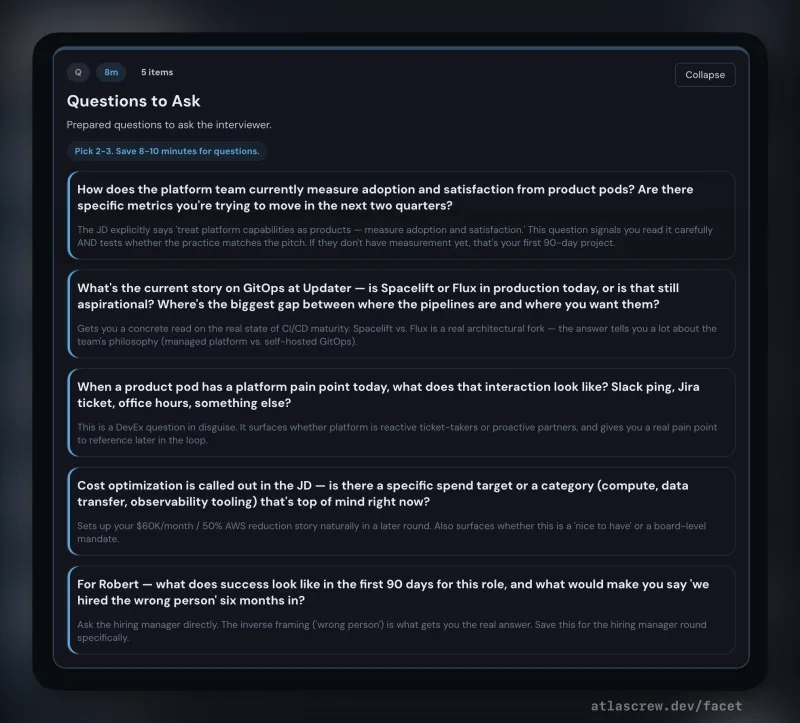
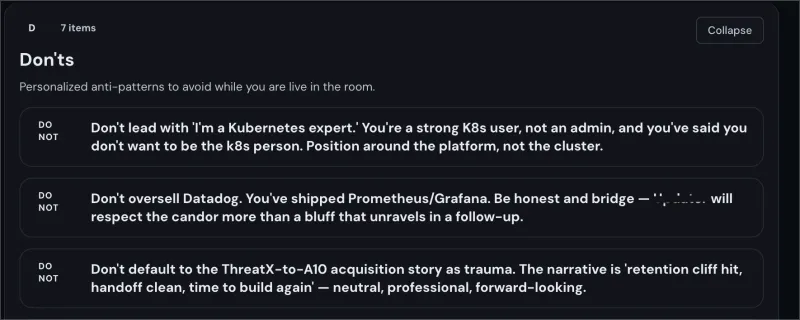
Round-specific prep decks with structured per-interviewer intel — role, background, what they care about, and a line tuned to each person's specific concern. Scenario cards with decision trees, anchor stories with sub-decisions, honest-bridge scripts for gap-framing. Homework mode for practice; live mode with keyboard shortcuts and timers for the conversation itself.
Build
Resume regenerated per opportunity from your identity model. Per-bullet include/exclude, role-specific targeting, PDF render with live preview. Themes, density controls, and round-trippable JSON export.
Letters
Cover letters drafted from pipeline context — opportunity, company research, and your assembled resume data. Paragraph-level targeting, reusable templates, tuned per letter.
What Facet replaces.
The spreadsheet of applications nobody updates.
Rounds, schedules, outcomes, per-round prep — in the entry, not a row.
The Claude-chat prep that died when the tab closed.
Prep decks persist. Generate once, refine across weeks, walk in prepared.
The pile of resumes in Downloads.
Resume regenerated per opportunity from your identity model.
The recruiter emails you lost track of.
Pipeline entries hold the thread — JD, comp, contacts, round schedule, prep state — in the entry.
The panel research you're too tired to do cold.
You supply the names from the invite. Facet does the deep per-person work.
What it looks like. Click any thumbnail to expand.
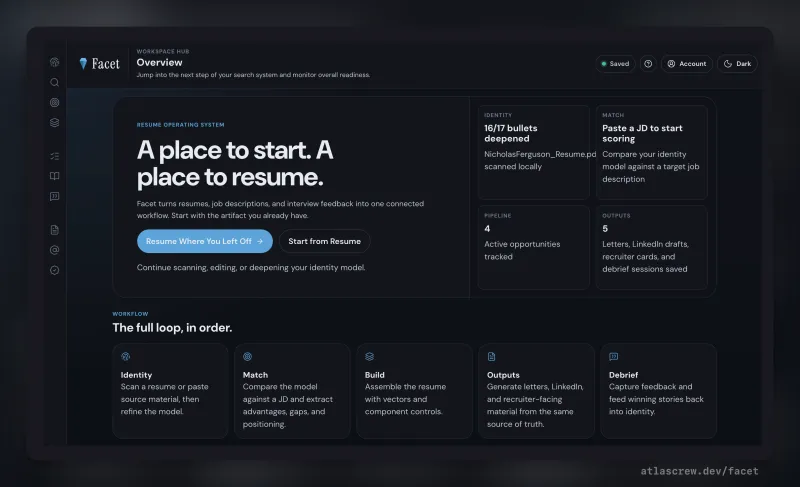
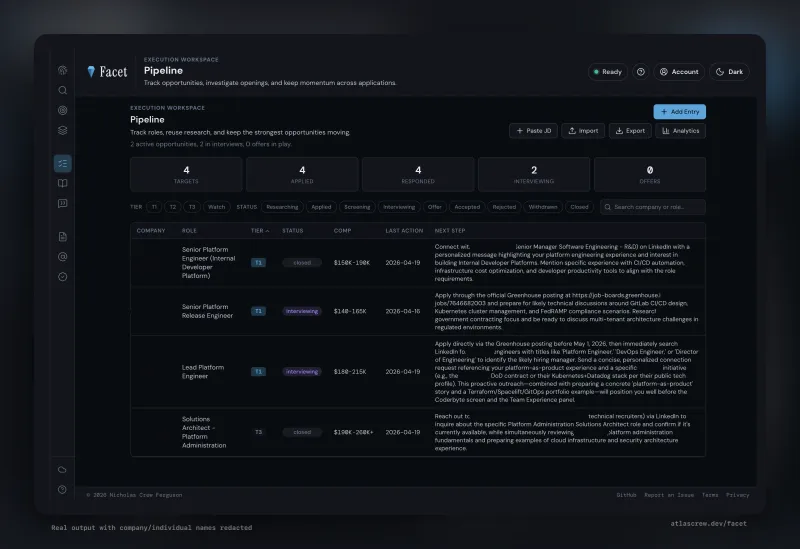
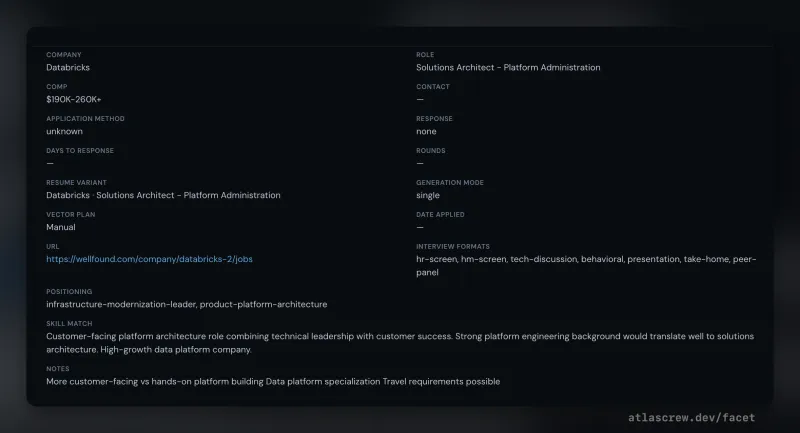
Free
- Vector-based resume builder — themes, density controls, PDF export
- JSON import/export for all data
- Manual pipeline tracking with analytics
- Manual interview prep and live companion
AI Pro
- Everything in Free
- JD analysis with AI-assisted bullet reframing
- Research profile inference and targeted job search
- AI-generated prep decks, cover letters, and LinkedIn cuts
- AI Live mode — your prepared knowledge, filtered per round
- Debriefs feed the model: each interview sharpens targeting
7-day refund · no questions asked
Self-Hosted
Your data is yours.
AGPL-licensed and self-hostable end to end. Run Facet on your own infrastructure for full custody — the license requires it stay open source.
In hosted mode, your data lives in managed Postgres with row-level security — tenant-scoped so Facet staff can't read your identity model, your pipeline, or your prep decks. Export encrypted backups any time; delete your account and the data goes with it.
Aggregate intelligence features (planned) are opt-in, never default-on. Anonymization threshold k ≥ 50 — no aggregate bucket reports fewer than 50 users. You can use Facet at full depth and share nothing.